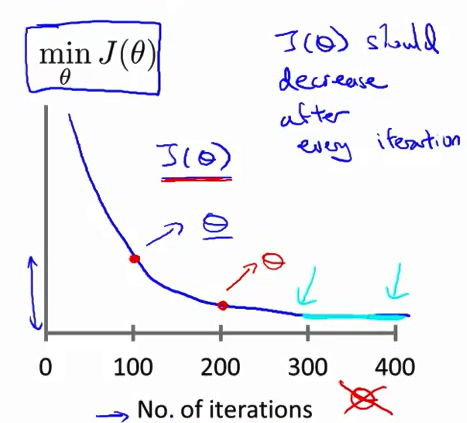
A cost function is something you want to minimize. For example, your cost function might be the sum of squared errors over your training set.
Gradient descent is a method for finding the minimum of a function of multiple variables. So you can use gradient descent to minimize your cost function.
If your cost is a function of K variables, then the gradient is the length-K vector that defines the direction in which the cost is increasing most rapidly. So in gradient descent, you follow the negative of the gradient to the point where the cost is a minimum.
If someone is talking about gradient descent in a machine learning context, the cost function is probably implied (it is the function to which you are applying the gradient descent algorithm).
To Know More Details-
cost Function
Gradient Descent
Gradient descent is a method for finding the minimum of a function of multiple variables. So you can use gradient descent to minimize your cost function.
If your cost is a function of K variables, then the gradient is the length-K vector that defines the direction in which the cost is increasing most rapidly. So in gradient descent, you follow the negative of the gradient to the point where the cost is a minimum.
If someone is talking about gradient descent in a machine learning context, the cost function is probably implied (it is the function to which you are applying the gradient descent algorithm).
To Know More Details-
cost Function
Gradient Descent